Dynamic Programming in Policy Iteration
11 Dec 2017
Richard Bellman was a man of many talents. In addition to introducing dynamic programming, one of the most general and powerful algorithmic techniques used still today, he also pioneered the following:
- The Bellman-Ford algorithm, for computing single-source shortest paths
- The term “the curse of dimensionality”, to describe exponential increases in search space as the number of parameters increases
- Many contributions to optimal control theory, artificial intelligence, and reinforcement learning.
In this post, I’m going to focus on the latter point - Bellman’s work in applying his dynamic programming technique to reinforcement learning and optimal control. He introduced one of the most fundamental algorithms in all of artificial intelligence — that of policy iteration.
Value iteration is a method of finding an optimal policy given an environment and its dynamics model. I’ll describe in detail what this means later, but in essence what this means is that due to Richard Bellman and dynamic programming it is possible to compute an optimal course of action for a general goal specified by a reward signal. This launched the field of reinforcement learning, which has recently seen some notably huge successes with AlphaGo Zero and systems which can learn to play complicated games directly from pixels.
This post is not a tribute to Richard Bellman, but he was a truly incredible computer scientist and someone whose life I find truly inspiring.
Markov Decision Processes
A Markov Decision Process (MDP) is a general formalization of decision making in an environment.
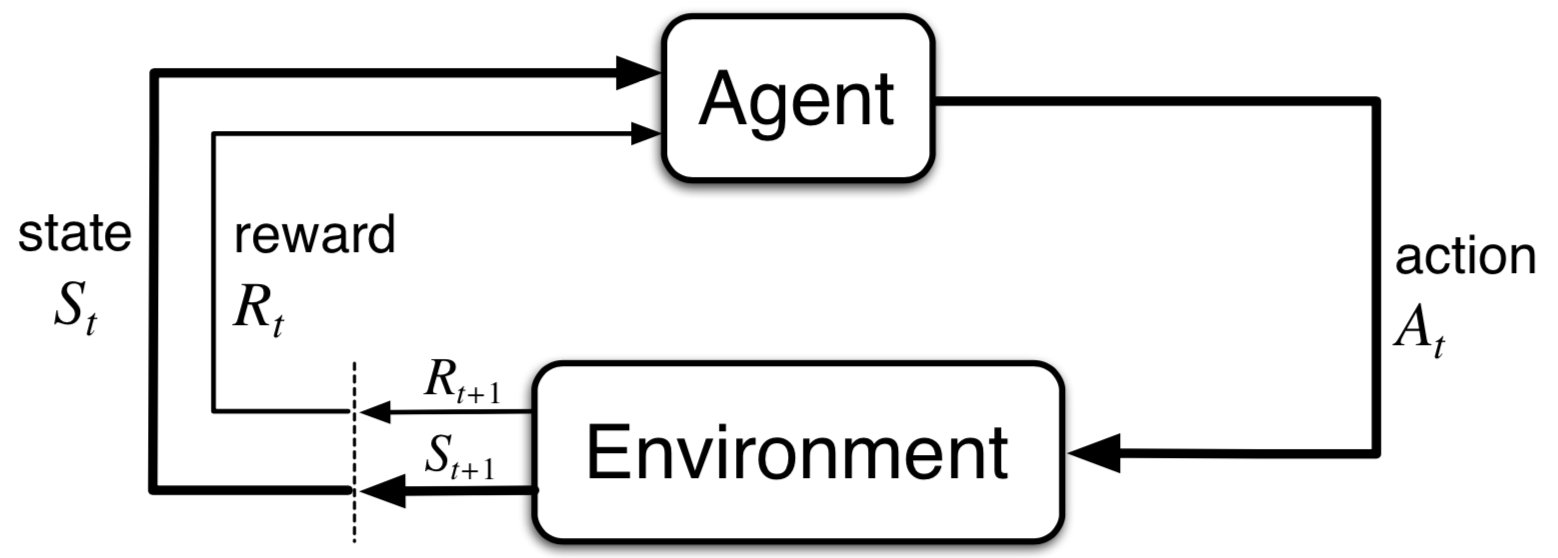
In reinforcement learning, there is an agent acting in an environment. At every iteration, an agent is acting in the environment. This agent sees the current state of the MDP, and based on this state it must choose some action. Once this action is taken, it sees the next state and it may receive some positive or negative reward. The goal of the agent is to act so as to maximize the total reward it receives. Here’s a specific example of what such an MDP might look like.
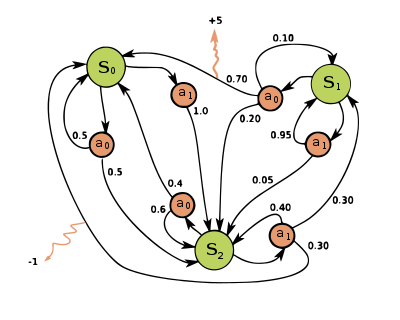
In this example, each of the green circles represent a state, so the set of states . Each of the red circles represents an action available in that state, so the set of actions . Moreover, note that a given action in some state may end up in more than one state, denoted by a probability associated with each arrow. These probabilities are given by some transition model :
For example, and . Finally, the yellow emitted lines represent rewards given on a state transition. Note that these rewards are associated with a state-action pair, and not just a state. These are given by the reward function which is dependent on a state-action pair.
It is up to the agent to act in such a way to see highly positive rewards often, and to minimize the number of highly negative rewards it encounters.
Let us come up with a formalization of this goal of the agent. We define a (deterministic) policy to be a mapping from state to action, that is:
A natural goal would be to find a policy that maximizes the expected sum of total reward over all timesteps in the episode, also known as the return :
Where denotes timestep of the end of the episode. Unfortunately, in some cases we might want to be , that is, the episode never ends. In this case, the sum would be an infinite sum and would diverge. To remedy this problem, we introduce a discount factor such that each reward gets weighted by a multiplicative term which is between 0 and 1:
Since our return may be different every time, because taking the same action in a given state may lead to different results according to the transition model, we want to maximize the expected cumulative discounted reward. This is known as the optimal policy :
This is the reinforcement learning problem. Given an MDP as a 5-tuple , find the optimal policy that maximizes expected cumulative discounted reward.
Value Iteration
The policy iteration algorithm computes an optimal policy for an MDP, in an iterative fashion. It has been shown to converge to the optimal solution quadratically — that is, the error minimizes with where is the number of iterations. This algorithm is closely related to Bellman’s work on dynamic programming.
Value functions
Before we describe the policy iteration algorithm, we must establish the concept of a value function. A value function gives a notion of, on average, how valuable a given state is. A value function answers the question, “what is the reward I should expect to get from being in a given state?”. Formally, a value function is defined to be:
In other words, the value function defines the average return given that you start in a given state and continue forward with the policy until the end of the episode.
The Bellman equation
Importantly, Bellman discovered that there is a recursive relationship in the value function. This is known as the Bellman equation, which is closely related to the notion of dynamic programming:
Ideally, we want to be able to write recursively, in terms of some other values for some other states . This would allow us to recursively find the value function for a given policy . It turns out that the recursive formulation is exactly this:
Visually, it may look like there’s a lot going on in this recursive formulation, but all it’s doing is performing an expected value over actions of the expected return from that action. Each expected value of an action is itself an expected value over possible next states and rewards. Using this equation, we can easily derive an iterative procedure to calculate .
The policy iteration algorithm
The main idea is that this can be done in an iterative procedure. At every iteration, a sweep is performed through all states, where we compute:
Note that if we are given the MDP , as well as some policy , this is something we have all the pieces to compute. As we perform this iteratively, the changes in value function will become smaller and smaller and will eventually converge (quadratically) at the true . Of course, we can’t perform an infinite number of iterations, so typically we just say that if the total change of the value function is below some small threshold, stop the procedure.
A worked-through example—grid world
Let’s say that we have some grid, and our agent can move in any direction. We define the grid world with a reward of +1 at the top right corner, and -1 at the bottom right corner. Once an agent reaches one of these corners, the episode ends. This looks like this:

Notice also how there is a wall in the middle of the map, which prevents movement in that direction. Notably, here we are going to say that the discount factor , and there is no noise - that is, each action deterministically takes the agent to the next state pointed to by the arrow.
For now, let’s define our policy to be the policy that moves in any valid direction with equal probability. This is known as the equiprobable policy.
In value iteration, at every iteration then, each state’s value will become the average of the states surrounding it. This table-filling behavior will converge to the correct value function, , as can be seen in the following animation:

Notice how this is a special case of dynamic programming, which fills a table which is in the shape of the environment. We can then perform policy improvement by greedily improving the policy with respect to the new value function.
Since our environment is deterministic, is where the arrow points, and everywhere else. Also, since and everywhere but the terminal states, the policy improvement update greedily chooses the direction which maximizes the value of the future state. This can be seen graphically here:
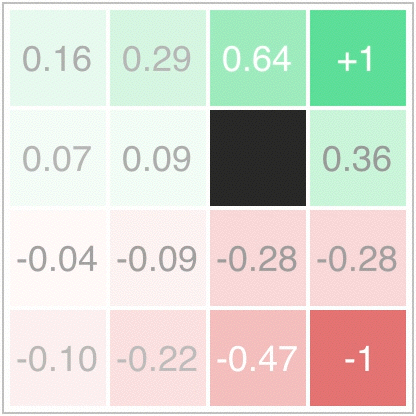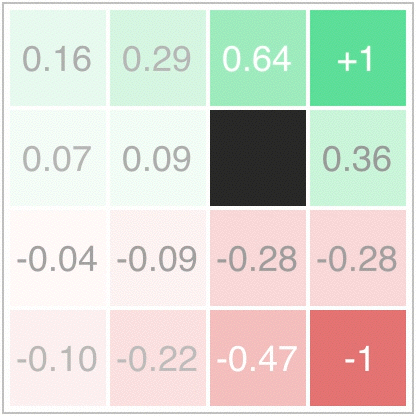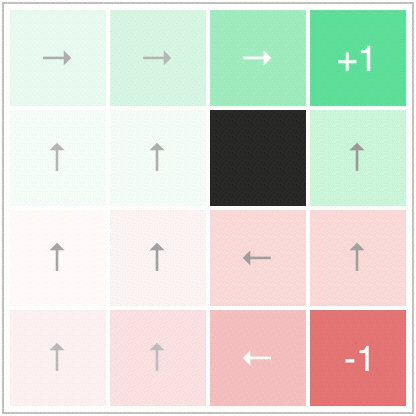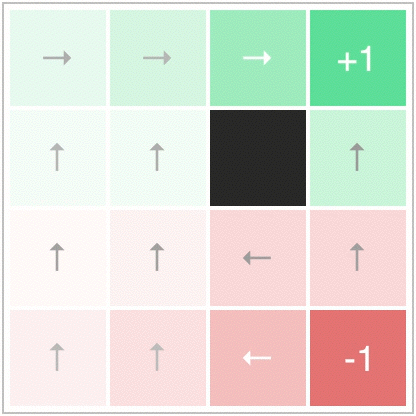
Now this policy could be evaluated, and we could alternate between policy evaluation (finding a value function for ) and policy improvement (greedification of the policy with respect to the value function):
And, as can be seen, we would eventually reach the optimal policy and value function for the environment. Note that this policy that was found for the environment in one iteration of the algorithm did not find the shortest path to the positive reward. If we wanted to do this, we would need to modify our MDP to encourage this. We could have done this in two ways:
- Add in a discount factor such that states closer to the reward state will have a higher discounted reward than further states
- Add in a constant, small negative reward of for every timestep where the reward is not reached.
Then, the algorithm would find a shortest path to the positive reward terminal state.
Policy iteration is one of the foundational algorithms in all of reinforcement learning and learning optimal control. We introduced the concepts of a Markov Decision Process (MDP), such as expected discounted reward, and a value function. We then informally derived the algorithm for policy iteration, and showed visually how it finds the optimal policy and value function.